
Voorbeeld vervaardigen LGM in 10 stappen
De stappen die uitgaande van een semantisch gegevensmodel leiden tot een logisch gegevensmodel lichten we toe aan de hand van het voorbeeld van een leverings-informatiesysteem. Het uitgangspunt vormt (een onderdeel van) het semantisch gegevensmodel voor de administratie van leveringen. We zien in dat model de volgende gegevenstypen met hun eigenschappen:
Levering
wordt geleverd aan klant;
vindt plaats op dag;
{bestaat uit de afgifte van artikelsoort in hoeveelheid};
heeft als totaalprijs bedrag.
Klant
wordt geïdentificeerd door klantnummer;
woont op adres;
wenst goederen te ontvangen op adres;
wordt aangeduid met naam;
{ontvangt levering}.
Artikelsoort
wordt geïdentificeerd door artikelcode;
wordt aangeduid met naam;
{komt voor in levering in hoeveelheid};
{wordt verkocht tegen bedrag gedurende periode}.
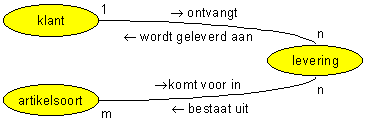
Stap 1: het afleiden van de basisstructuur
Op dit diagrampassen we de afleidingsregels toe. Dit resulteert in het onderstaande diagram.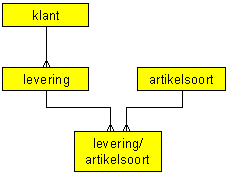
Stap 2: het verwijderen van overtollige relaties
In dit model zijn geen overtollige relaties aanwezig, dus in deze stap verandert niets.
Stap 3: keuze van de primaire sleutels
We kiezen nu de primaire sleutels voor de onderkende tabellen, vier in getal.
- voor de tabel KLANT wordt klantnummer gekozen:
Het klantnummer is bedrijfsbreed ingevoerd en wordt voor de communicatie met de klant gebruikt. Zowel de medewerkers van het bedrijf als de klant kennen het nummer; dit is dus een sleutel van type 1. - voor de tabel LEVERING wordt een leveringnummer geïntroduceerd en als primaire sleutel gekozen:
Een levering wordt voor de gebruikers geïdentificeerd door het klantnummer en de leverdatum (er wordt maar één keer per dag geleverd). Omdat leveringen voor één dag op verschillende momenten en door verschillende personen kunnen worden ingevoerd – die dan vervolgens bij de feitelijke uitlevering als een geheel worden behandeld – wordt besloten een intern, verborgen administratief nummer te introduceren. Dit leveringnummer is een sleutel van type 3. - voor de tabel ARTIKELSOORT wordt artikelcode gekozen:
Deze artikelcode wordt algemeen gebruikt (onder andere in de productcatalogus) en is dus net als klantnummer een sleutel van type 1. - voor de tabel LEVERING/ARTIKELSOORT wordt gekozen voor de combinatie van leveringnummer en artikelcode:
Omdat hier twee eigenschappen gecombineerd worden zou je geneigd kunnen zijn deze sleutel van type 2 te beschouwen. Omdat het leveringnummer echter een type-3-sleutel is in een eerder onderkende tabel, is de combinatie ook van dit type. Dit betekent, dat deze sleutel niet als zodanig door de gebruikers kan worden gebruikt.
Nu de primaire sleutels zijn bepaald kunnen we de eerste beschrijving van de tabellen geven.
- KLANT (klantnummer, .....);
- LEVERING (leveringnummer, ......);
- ARTIKELSOORT (artikelcode, ......);
- LEVERING/ARTIKELSOORT (leveringnummer, artikelcode, .......);
Stap 4: het toevoegen van externe sleutels aan de tabellen
In ons voorbeeld zien we drie relaties tussen tabellen. Daaruit zou je kunnen concluderen, dat bij drie externe sleutels dienen te worden toegevoegd. Het blijkt er echter slechts één te zijn.
De relatie tussen de tabellen KLANT en LEVERING leidt tot het toevoegen van een externe sleutel in de tabel aan de n-zijde van de relatie: LEVERING. Aan deze tabel wordt het attribuuttype klantnummer toegevoegd.
De relaties tussen de tabellen LEVERING/ARTIKELSOORT en LEVERING respectievelijk ARTIKELSOORT worden reeds bewaakt doordat de primaire sleutel van LEVERING/ARTIKELSOORT is samengesteld uit de sleutels van de andere twee. Dit hangt samen met het feit, dat deze tabel is ontstaan als gevolg van het oplossen van een m:n-relatie. Hier hoeven dus geen nieuwe externe sleutels te worden toegevoegd.
Na deze stap kunnen we de beschrijving als volgt uitbreiden.
- KLANT (klantnummer, .....);
- LEVERING (leveringnummer, klantnummer, ......);
- ARTIKELSOORT (artikelcode, ......);
- LEVERING/ARTIKELSOORT (leveringnummer, artikelcode, .......);
Stap 5: Het behandelen van repeterende attribuuttypen
In ons voorbeeld is sprake van vier repeterende gegevenstypen in het semantisch gegevensmodel.
Levering {bestaat uit de afgifte van artikelsoort in hoeveelheid}.
Klant {ontvangt levering}.
Artikelsoort {komt voor in levering in hoeveelheid};
Artikelsoort {wordt verkocht tegen bedrag gedurende periode}.
Twee hiervan zijn reeds in een nieuwe, afzonderlijke tabellen afgesplitst:
Levering {bestaat uit de afgifte van artikelsoort in hoeveelheid}.
Artikelsoort {komt voor in levering in hoeveelheid};
De derde betreft een bewering die, als inverse, synoniem is met een andere, namelijk
Levering wordt geleverd aan klant.
Aangezien dit geen repeterend attribuuttype betreft, wordt dit attribuuttype in het model opgenomen. Het gegevenstype klant {ontvangt levering} kan daaruit worden afgeleid.
Het overblijvende attribuuttype dient nu nog in een afzonderlijke tabel te worden ondergebracht:
Artikelsoort {wordt verkocht tegen bedrag gedurende periode}.
Als gevolg hiervan ontstaat de tabel ARTIKELPRIJS. Voor deze tabel bepaal je vervolgens ook de primaire sleutel en de externe sleutel.
De beschrijving van de tabellen luidt nu als volgt.
- KLANT (klantnummer, .....);
- LEVERING (leveringnummer, klantnummer, ......);
- ARTIKELSOORT (artikelcode, ......);
- LEVERING/ARTIKELSOORT (leveringnummer, artikelcode, .......);
- ARTIKELPRIJS (artikelcode, periode, verkoopprijs, .....)
Het Bachman-diagram moet nu ook aangepast worden. Dit komt er als volgt uit te zien:
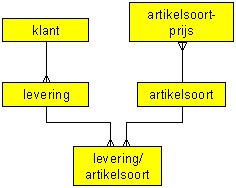
![]() Het model bevindt zich nu in de eerste normaalvorm.
Het model bevindt zich nu in de eerste normaalvorm.
Stap 6: toevoegen van de overige attribuuttypen aan de tabellen
Aan de tabellen worden de nog ontbrekende attribuuttypen toegevoegd. Hiermee ontstaan de volgende tabelbeschrijvingen.
- KLANT (klantnummer, woonadres, ontvangstadres, klantnaam);
- LEVERING (leveringnummer, klantnummer, leverdatum, totaalprijs);
- ARTIKELSOORT (artikelcode, artikelnaam);
- LEVERING/ARTIKELSOORT (leveringnummer, artikelcode, leverhoeveelheid);
- ARTIKELPRIJS (artikelcode, periode, verkoopprijs)
Stap 7: verwijderen van afleidbare attribuuttypen
Stel dat een gegevensregel is geformuleerd dat de totaalprijs van een levering afgeleid kan worden uit de verkoopprijs van de artikelsoorten en de hoeveelheden van elk artikelsoort die geleverd worden. (Merk op, dat dit niet in alle gevallen voor de hand liggend is. Denk aan kwantumkorting of regelingen met betrekking tot levertijden.) Het gegevenstype ‘Levering heeft als totaalprijs bedrag’ is dan afleidbaar en wordt derhalve niet in een tabel bijgehouden. Daarmee worden onderhoudsproblemen voorkomen.
Het verwijderen van afleidbare gegevens moet altijd gepaard gaan met het documenteren van de afleidingsregels, zoals gespecificeerd in het semantische gegevensmodel.
Na deze stap luiden de tabelbeschrijvingen als volgt.
- KLANT (klantnummer, woonadres, ontvangstadres, klantnaam);
- LEVERING (leveringnummer, klantnummer, leverdatum);
- ARTIKELSOORT (artikelcode, artikelnaam);
- LEVERING/ARTIKELSOORT (leveringnummer, artikelcode, leverhoeveelheid);
- ARTIKELPRIJS (artikelcode, periode, verkoopprijs)
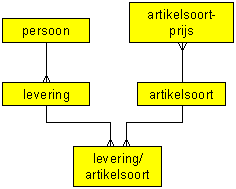
Stap 8: stabiliseren van het model
De KLANT-tabel kan vervangen worden door een PERSOON-tabel. Hoewel aan een dergelijke generalisatie op dit moment nog geen behoefte bestaat, is het mogelijk dat ook gegevens over leveranciers bijgehouden moeten worden. In die gevallen kan een dergelijke generalisatie nuttig blijken.
Als je hiertoe besluit, moet je een attribuuttype soort-persoon opnemen dat de waarde "klant" of "leverancier" kan krijgen.
Een extra regel die moet worden toegevoegd is, dat een levering alleen aan een persoon van de soort "klant" kan zijn gerelateerd.
De tabelbeschijvingen en het diagram veranderen overeenkomstig.
- PERSOON (persoonnummer, woonadres, ontvangstadres, klantnaam);
- LEVERING (leveringnummer, persoonnummer, leverdatum);
- ARTIKELSOORT (artikelcode, artikelnaam);
- LEVERING/ARTIKELSOORT (leveringnummer, artikelcode, leverhoeveelheid);
- ARTIKELPRIJS (artikelcode, periode, verkoopprijs)
Stap 9: het toevoegen van tijdsaspecten en andere beheergegevens
In het model nemen wij de volgende beheerattributen op:
- in de tabel PERSOON nemen wij de registratiedatum op. Zo kunnen wij met terugwerkende kracht overzichten van het aantal in de administratie aanwezige klanten (of leveranciers) produceren.
- In de tabel LEVERING nemen wij de registrator en registratiedatum op. Daarmee kunnen wij bij twijfel over de juistheid van de geregistreerde leveringen tevens nagaan waar we ons kunnen informeren. (Het opnemen van de registrator is een grensgeval; het had heel goed mogelijk geweest dat deze controlemogelijkheid al op gebruikersniveau was onderkend.)
- In de tabellen LEVERING en LEVERING/ARTIKELSOORT nemen wij ook de datum van laatste raadpleging op. De veronderstelling is, dat leveringen die afgehandeld zijn (dus ook gefactureerd en betaald) en waarvoor niemand meer belangstelling heeft na vijf jaar uit de administratie verwijderd mogen worden.
- PERSOON (persoonnummer, woonadres, ontvangstadres, klantnaam, registratiedatum);
- LEVERING (leveringnummer, persoonnummer, leverdatum, registrator, registratiedatum, raadpleegdatum);
- ARTIKELSOORT (artikelcode, artikelnaam);
- LEVERING/ARTIKELSOORT (leveringnummer, artikelcode, leverhoeveelheid, registrator, registratiedatum, raadpleegdatum);
- ARTIKELPRIJS (artikelcode, periode, verkoopprijs)
![]() De registrator wordt geïdentificeerd door het medewerkersnummer. Daarmee wordt verwezen naar de tabel medewerker elders in de administratie. Als deze relatie automatisch bewaakt moet worden (wat voor de hand ligt) dient deze tabel ook in het LGM opgenomen te worden.
De registrator wordt geïdentificeerd door het medewerkersnummer. Daarmee wordt verwezen naar de tabel medewerker elders in de administratie. Als deze relatie automatisch bewaakt moet worden (wat voor de hand ligt) dient deze tabel ook in het LGM opgenomen te worden.
Stap 10: controle op de Boyce-Codd normaalvorm
Het model bevindt zich in de Boyce-Codd normaalvorm.